


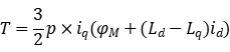
翻譯自——nextplatform,Nicole Hemsoth
Carey Kloss在過去幾年密切參與了人工智能硬件的崛起,其中最引人注目的是他構建了第一臺Nervana計算引擎。英特爾(Intel)利用這臺引擎將其開發成兩種獨立的產品:一種用于訓練,另一種用于推理。
他告訴nextplatform,真正的訣竅是跟上具有平衡架構的培訓模型的規模和復雜性不斷增長的步伐。考慮到培訓所需的計算幾乎每季度翻一番,從性能、效率和可伸縮性的角度來看,這比以往任何時候都更重要。

Kloss和英特爾認為,他們終于用Spring Crest深度學習加速器(或者更簡單地說,英特爾Nervana NNP-T)找到了平衡的法則。這個名字可能不像“Volta”這樣富有詩意,但我們從它目前的狀態來看,它很有競爭力,并且在性能/效率和數據移動潛力方面填補了一些空白。
英特爾/Nervana的硬件團隊已經采取了一種切實可行的方法,與一些超大規模的公司合作構建一種平衡的芯片,考慮到Facebook是其中的佼佼者,這家社交巨頭計劃讓英偉達的GPU在培訓方面擁有更強的競爭力,假設這是一個推論。在我們今年5月舉行的下一次人工智能平臺活動上,Facebook基礎設施主管Vijay Rao指出,他們期待著嘗試任何能夠在培訓和推理方面具備規模優勢的架構。
最后,在Hot Chips上,我們看到了更多的關于這個架構的信息,包括一些關于自定義網絡Kloss的深入了解,Kloss在收購前幫助最初的Nervana計算引擎構建了這個網絡。這個架構給我們留下深刻印象的是,它是為可伸縮性而設計的。雖然確實可以對GPU進行伸縮,但對于大型培訓集群來說,按比例移動數據一直是一個棘手的問題。
Nervana/Intel的優勢在于,就是從最開始設計培訓架構時就只考慮到工作量,尤其是在大多數培訓模式不再適合最大芯片的情況下。這意味著專注于向外擴展是有道理的,除了強大的數學單元之外,還需要一些創造性的內存、SerDes和其他HBM技巧。
對于幾乎所有的模型,大多數時間都花在乘法/累加(矩陣數學或卷積)上,這意味著需要大量的計算(GPU擅長的東西),但是大量的讀取意味著可以反復使用一塊數據,理想情況下從HBM讀取一次并使用并行乘法器多次。這是一個很標準的思考訓練問題的方法。Kloss說,當他們深入研究工作負載時,乘數、SRAM和最快的HBM是關鍵,但是平衡起來要困難得多。“需要有足夠的SRAM來滿足乘數、足夠的高速SerDes芯片和HBM,每個都有相同的限制,給定相同的HBM規格。因此,這就是平衡內存、啟動內存和關閉內存、網絡和計算的訣竅。”

這個平面圖,顯示了4 HBM2和64通道SerDes與中心計算(24張量處理器/TPCs)、SRAM、PCIe Gen 4 x 16EP和控制塊之間的平衡。芯片上共有60mb的分布式內存,全部采用2.5D封裝。
其中一個很酷的功能,也是大多數地方都沒有注意到的創新,是基于臺積電晶圓片上基板(CoWoS)技術。這是一個相當大的die,但考慮到人工智能的工作負載,尺寸為680mm。但是,這與中介層(interposer)沒有邏輯關系,它是被動的,在給定設計目標的情況下,這是一個明智的權衡。
下面是我們對TPC[1]的一個真實理解。我們的設計目標是盡可能減少模具面積,包括控制路徑邏輯,以及OCP/OAM規格尺寸是固定的。“我們不想把模具區浪費在我們不需要的東西上,”Kloss解釋說。我們的指令集很簡單;矩陣乘法,線性代數,卷積。我們沒有寄存器,一切都是2D、3D或4D的張量。軟件中定義了很多東西,包括在打開或關閉die模型時編寫相同程序的能力。你可以把它想象成一個等級層次;可以使用相同的指令集在一個組中的兩個集群之間移動數據,或者在組之間移動數據,甚至在網絡中的晶圓。最終的目的是我們想讓軟件管理通信變得更簡單。”

這將消耗150-200瓦的電量,但這是一個基于ResNet 50部分的推測結果,正如我們所知,這在現實世界中并不具有代表性。我們要到明年才能看到英特爾MLperf的結果,但是Kloss說到那時他們會有幾個基準測試,包括自然語言處理和其他工作負載。

紅色塊是復合數學管道,在這里,矩陣乘法的前運算和后運算可以用乘數數組中的部分乘積來完成,而不需要另一個內存端口來將部分乘積輸入紅色區域。這樣就可以在任何周期上獲得輸出(預激活和后激活),并且它與保存在張量中的兩個輸出張量完全管道化。
到目前為止,我們所看到的一切都回避了一個重要的問題。除了在硅上的一些明顯差異外,它的數學單元與Nvidia Volta GPU或TPU 3的張量有什么不同呢?畢竟,乘數不就是乘數嗎?
答案可能比看上去要微妙一些。這涉及到權衡取舍、die area和數據移動。
“像這樣的乘法器陣列或其他競爭對手,你可以用乘法器得到更密集的數據。一旦你有了密集的乘法器陣列,你就可以用更少的模具面積來做這些乘法器,你可以用你的模具面積來做更多的信息分配或其他事情,”Kloss說。下一個決定是量化(矩陣本身的量化相乘,而不是權重或數據)。英特爾選擇32×32,是因為當他們觀察通過神經網絡運行的尺寸時,它似乎不那么浪費,尤其是在邊界條件下。
“如果你想在一個32×32的數組上做一個33×33的乘法,你將會浪費大量的時間在無意義的乘法上,”Kloss解釋道。“所以,如果你有一個更大的乘法器陣列(如TPU中的128×128或256×256),它會通過巨大的矩陣乘法進行運算,但每次遇到邊界條件,它就會浪費一些乘數——它們不會被使用。”他的團隊分析了更大的死區權衡 (64 64×128×128)但因為有特定數量的TPC和定義內存,使得他們無法得到另一個行或列的TPC面積密度的儲蓄。
“節省下來的錢不足以讓我們再建一排或一列,而且我們受到模具尺寸的限制——這是回到了Lake Crest第一代神經網絡。供應商能構建的量是我們的上限。所以32×32的消元過程是正確的權衡。今天來看,這似乎是一個很好的權衡,一方面不浪費很多乘法器,另一方面擁有足夠密集的乘法器陣列。
請記住,在開始使用TPU時,谷歌團隊嚴格使用256×256,但是在第二個版本中,隨著工作負載的變化和更多實際模式的出現,谷歌團隊減少到128×128。每個芯片上有兩個這樣的數組v2和v3,每個芯片上有四個這樣的數組。另一邊的Volta GPU采用了不同的路徑,使用4x4x4矩陣(3D而不是2D)。在這一點上進行比較仍然困難,這意味著2020年MLperf的培訓結果將更加有趣。
為了在更小的進程節點上獲得類似的性能,而SRAM要少得多,它們就必須有更大的die區域。我們可以增加更多的SRAM和更快的網絡,因為我們正在用一個更簡單的指令集。在這一點上,更有效地利用模具面積將提供直接的動力和性能效益。”
順便提一下,關于英特爾如何談論事物的一個快速澄清點:一切都是一個張量。他們不討論權重,那些只是被認為是另一個“張量”,但是,正如Kloss解釋的那樣,“我們確實在SRAM中保留了權重,如果它們足夠小的話。”我們可以完全控制軟件。如果足夠小,它們可以存儲在本地內存中,但是如果它們更大,我們可以將它們從HBM雙緩存到藍色區域,然后再返回。乘法器陣列只需要從內存庫中獲取任何權重或非權重的數據,然后讀入、乘法器陣列,然后再把它們吐出來。”
我們期望Nervana和Intel能夠提供一些定制的功能,其中包括一個復雜的微控制器,它允許定制指令處理工作,而不會使寶貴的模具區域復雜化。可以從HBM中提取幾個子例程來運行集群上的任何東西,生成驅動SRAM和乘數的底層指令。這對于像ROI這樣的事情很方便。在這種情況下,不需要特殊的邏輯,只需要一個子例程就可以創建一條新的指令。這也有助于許多批次的動態形狀和大小的可用性。
NNP-T同時存在于PCIe和夾層因子中。“我們喜歡OAM規范;因為它更容易冷卻和逃離這么多高速SerDes的載體,”Kloss說到。
“你可以看到PCIe卡和兩個白色的連接器,然后是芯片背面的四個QQSFP連接器:我們必須做所有這些來避開PCIe卡上的所有SerDes,但是對于夾層卡,它都在那里,可以安裝在任何OCP或OAM夾層底盤上。這將打開一個完全連接的載波卡或混合網格立方體載波卡的組合(我們更喜歡這樣做,因為這意味著在機箱內部少了一個鏈接)。他說,英特爾不只是想在一個機箱中擴展這些,而是從一個機箱到另一個機箱,從一個機箱到另一個機箱,因此更多的SerDes從機箱的后部出來是很重要的。此外,我們的專有鏈接速度非常快,延遲也很低,所以在機箱外添加額外的跳轉不會影響性能。在其他人可能更喜歡完全連接的地方,我們認為最好讓更多的SerDes從盒子里出來,使用混合網格立方體。”
延伸閱讀
一款基準測量工具的雛形——MLPerf
由各大領先的科技公司和大學組成的團隊發布了一款基準測量工具的雛形——MLPerf,其目的是測量各種AI框架和芯片中不同機器學習任務的訓練速度和推理時間。

MLPerf的誕生是小部分公司自我組織進行產品對比的結果。在很長一段時間內,人們都在討論是否有必要設立一個有意義的AI基準。支持者認為,標準的缺失限制了AI的應用。
MLPerf聲明它的基礎目標是:
用公平、有幫助的測量方法加速機器學習的發展
對各競爭系統進行公平對比,以鼓勵機器學習的發展
保證讓所有人都能參與基準評比
既服務于商業群體,也服務于研究領域
基準要可復制,確保結果的可靠
英特爾收購Nervana后的第一張王牌Lake Crest,號稱比GPU速度快10倍,年底測試
人工智能硬件平臺爭奪的序幕才剛剛拉開。隨著時間的推移,人們很快發現相比GPU和CPU,FPGA具有的低能耗、高性能以及可編程等特性,十分適合感知計算,而且可以做到快速部署。2015年,英特爾便動用167億美元收購了當時全球第二大FPGA廠商Altera,也是有史以來最大的一筆收購案。
也是在那一年,憑借擁有號稱最快的深度學習框架 neon和首個結合機器智能軟硬件云服務的Nervana Cloud,深度學習初創公司 Nervana 被 VentureBeat 評為值得關注的五家深度學習初創公司,次年8月,暗中觀察許久的英特爾豪擲4億美元將僅有48名員工的Nervana收入了囊中。

在整合了 Nervana 的技術之后,英特爾AIPG 計劃推出 Crest 家族系列產品線。首先亮相的是一款叫做 Lake Crest 的芯片,它是專為訓練DNN而深度定制的ASIC解決方案,預計今年下半年測試,2018年上市。據 Naveen Rao 曾經對媒體介紹,相對于目前最快的GPU, Lake Crest的加速性能是它的10倍。
[1] 在半導體研究和制程上,包括質量判定時,TPC是 Thermo Pressure Cook 中文簡稱高溫高壓測試,是半導體質量關鍵點。
上一篇:凌華科技嵌入式顯卡助力提升嵌入式應用的性能
下一篇:中國首款車規級AI芯片,地平線“征程二代”正式量產
推薦閱讀
史海拾趣
在追求經濟效益的同時,A/D Electronics Inc也積極履行社會責任,致力于可持續發展。公司注重環保和節能,采用環保材料和節能技術,減少生產過程中的環境污染和資源消耗。此外,公司還積極參與公益事業,為社會做出貢獻。通過這些舉措,A/D Electronics Inc不僅贏得了社會的廣泛認可,也為企業的長遠發展奠定了堅實基礎。
這些故事雖然基于虛構,但它們反映了電子行業發展的一般規律和趨勢,包括技術創新、市場拓展、品質管理、人才培養以及社會責任等方面。這些元素對于任何一家在電子行業中發展起來的公司來說,都是不可或缺的。
隨著電子行業的快速發展,Compex Corporation意識到只有不斷創新才能在市場中保持競爭力。因此,公司加大了在研發方面的投入,積極引進先進的技術和設備。XXXX年,公司成功研發出了一款具有革命性的新型電容器,其性能遠超市場上的同類產品。這一技術突破不僅提升了公司的技術水平,也進一步鞏固了其在市場中的地位。
面對日益激烈的市場競爭和快速變化的市場需求,HCC Industries在2020年啟動了數字化轉型計劃。公司投入大量資金引入先進的自動化生產線和智能化管理系統,實現了從原材料采購到成品出廠的全鏈條數字化管理。這一舉措不僅大幅提高了生產效率和產品質量,還降低了運營成本和庫存風險。同時,HCC還利用大數據和人工智能技術優化產品設計和市場策略,進一步提升了其市場競爭力。
隨著數字化時代的到來,APDI意識到數字化轉型對于提升公司運營效率和市場競爭力的重要性。公司開始引入先進的生產管理系統和數據分析工具,實現了生產過程的自動化和智能化。同時,APDI還加強了與客戶的在線互動和定制化服務,提升了客戶滿意度和忠誠度。數字化轉型使APDI在激烈的市場競爭中保持了領先地位。
這些故事是基于電子行業的一般趨勢和可能的公司發展路徑虛構的,旨在展示一個假設公司在不同發展階段的可能經歷。它們并不代表任何真實公司的歷史或情況。
隨著公司業務的不斷發展,DEI公司開始考慮國際化拓展。他們積極尋求與國際知名企業的合作,通過技術交流和共同研發,不斷提升自身實力。同時,DEI公司也在全球范圍內建立了銷售網絡,將產品推向了更廣闊的市場。這一舉措不僅提高了公司的知名度,也為公司帶來了可觀的收益。
在技術創新方面,啟攀微電子一直致力于提升產品的性能和可靠性。公司擁有一支技術骨干團隊,他們擁有豐富的芯片設計開發和批量生產的經驗。通過不斷的技術創新和優化,公司成功推出了多款高性能、低成本的芯片產品,并在通訊、智能家電及個人消費類等高速成長的電子信息領域取得了廣泛的應用。同時,公司還積極拓展海外市場,成功將產品打入韓國等國家和地區,進一步提升了公司的國際影響力。













 XC6401HF12DML
XC6401HF12DML- 臺積電:制造的芯片離開工廠之后,很難監控它們的走向和用途
- E3650工具鏈生態再增強,IAR全面支持芯馳科技新一代旗艦智控MCU
- 瑞薩電子廣受歡迎的RA0系列推出新產品, 卓越的功耗、更寬的溫度范圍
- 英飛凌推出全球首款集成肖特基二極管的工業用GaN晶體管產品系列
- e絡盟擴展無源產品解決方案,簡化工程師和買家體驗
- 優化效率:探索有源鉗位正激轉換器的二次整流電路設計和占空比的作用
- Windows Arm64 托管運行器正式支持 GitHub Actions,加速開發流程
- 高頻逆變器有哪些特性?高頻逆變器變壓器屏蔽是怎么回事
- KSC XA輕觸開關提供聲音柔和的輕觸反饋,增強用戶體驗
- 逆變器如何接線?逆變器高頻化?高性能化?







 京公網安備 11010802033920號
京公網安備 11010802033920號