由于采用了多攝像頭輸入和深度卷積骨干網(wǎng)絡(luò),用于訓(xùn)練自動(dòng)駕駛感知模型的 GPU 內(nèi)存占用很大。當(dāng)前減少內(nèi)存占用的方法往往會(huì)導(dǎo)致額外的計(jì)算開(kāi)銷(xiāo)或工作負(fù)載的失衡。
本文介紹了 NVIDIA 和智能電動(dòng)汽車(chē)開(kāi)發(fā)商蔚來(lái)的聯(lián)合研究。具體來(lái)說(shuō),文中探討了張量并行卷積神經(jīng)網(wǎng)絡(luò)(CNN)訓(xùn)練如何有助于減少 GPU 內(nèi)存占用,并展示了蔚來(lái)如何提高自動(dòng)駕駛汽車(chē)感知模型的訓(xùn)練效率和 GPU 利用率。
自動(dòng)駕駛的感知模型訓(xùn)練
自動(dòng)駕駛感知任務(wù)采用多攝像頭數(shù)據(jù)作為輸入,卷積神經(jīng)網(wǎng)絡(luò)(CNN)作為骨干(backbone)來(lái)提取特征。由于 CNN 的前向激活值(activations)都是形狀為(N, C, H, W)的特征圖(feature maps)(其中 N、C、H、W 分別代表圖像數(shù)、通道數(shù)、高度和寬度)。這些激活值需要被保存下來(lái)用于反向傳播,因此骨干網(wǎng)絡(luò)的訓(xùn)練通常會(huì)占據(jù)顯著的內(nèi)存大小。
例如,有 6 路相機(jī)以 RGB 格式輸入分辨率為 720p 的圖像,批大小(batchsize)設(shè)置為 1,那么骨干網(wǎng)絡(luò)的輸入形狀為(6, 3, 720, 1280)。對(duì)于如 RegNet 或 ConvNeXt 這樣的骨干網(wǎng)絡(luò)而言,激活值的內(nèi)存占用是遠(yuǎn)大于模型權(quán)重和優(yōu)化器狀態(tài)的內(nèi)存占用的,并且可能會(huì)超出 GPU 的內(nèi)存大小限制。
蔚來(lái)汽車(chē)自動(dòng)駕駛團(tuán)隊(duì)在這一領(lǐng)域的研究表明,使用更深的模型和更高的圖像分辨率可以顯著提高感知精度,尤其是對(duì)尺寸小和距離遠(yuǎn)的目標(biāo)的識(shí)別;同時(shí),蔚來(lái) Aquila 超感系統(tǒng)搭載 11 個(gè) 800 萬(wàn)像素高清攝像頭,每秒可產(chǎn)生 8GB 圖像數(shù)據(jù)。
GPU 內(nèi)存優(yōu)化需求
深度模型和高分辨率輸入對(duì)于 GPU 內(nèi)存優(yōu)化提出了更高的要求。當(dāng)前解決激活值 GPU 內(nèi)存占用過(guò)大的技術(shù)有梯度檢查點(diǎn)(gradient checkpointing),即在前向傳播的過(guò)程中,只保留部分層的激活值。而對(duì)于其他層的激活值,則在反向傳播的時(shí)候重新計(jì)算。
這樣可以節(jié)省一定的 GPU 內(nèi)存,但會(huì)增加計(jì)算的開(kāi)銷(xiāo),拖慢模型訓(xùn)練。此外,設(shè)置梯度檢查點(diǎn)通常需要開(kāi)發(fā)者根據(jù)模型結(jié)構(gòu)來(lái)選擇和調(diào)試,這給模型訓(xùn)練過(guò)程引入了額外的代價(jià)。
蔚來(lái)還使用了流水線(xiàn)并行技術(shù),將神經(jīng)網(wǎng)絡(luò)按照 GPU 內(nèi)存開(kāi)銷(xiāo)進(jìn)行平均分段,部署到多個(gè) GPU 上進(jìn)行訓(xùn)練。此方法雖然將存儲(chǔ)需求平分到多個(gè) GPU 上,但是因?yàn)橛?jì)算不平衡,會(huì)導(dǎo)致明顯的 GPU 間負(fù)載不均衡現(xiàn)象,一些 GPU 的計(jì)算資源無(wú)法被充分利用。
基于 PyTorch DTensor 的張量并行 CNN 訓(xùn)練
綜合考慮以上因素,NVIDIA 和蔚來(lái)合作設(shè)計(jì)并實(shí)現(xiàn)了張量并行(Tensor Parallel)卷積神經(jīng)網(wǎng)絡(luò)訓(xùn)練方案,將輸入值和中間激活值切分到多個(gè) GPU 上。而對(duì)于模型權(quán)重和優(yōu)化器狀態(tài),我們采用和數(shù)據(jù)并行訓(xùn)練相同的策略,將其復(fù)制到各個(gè) GPU 上。該方法能夠降低對(duì)單個(gè) GPU 的內(nèi)存占用和帶寬壓力。
PyTorch 2.0 中引入的 DTensor 提供了一系列原語(yǔ)(primitives)來(lái)表達(dá)張量的分布如切片(sharding)和重復(fù)(replication),使用戶(hù)能夠方便地進(jìn)行分布式計(jì)算而無(wú)需顯式調(diào)用通信算子,因?yàn)?DTensor 的底層實(shí)現(xiàn)已經(jīng)封裝了通信庫(kù),如 NVIDIA 集合通信庫(kù) (NCCL)。
有了 DTensor 的抽象,用戶(hù)可以方便地搭建各種并行訓(xùn)練策略,如張量并行(Tensor Parallel),分布式數(shù)據(jù)并行(Distributed Data Parallel)和完全切片數(shù)據(jù)并行(Fully Sharded Data Parallel)。
實(shí)現(xiàn)
以用于視覺(jué)任務(wù)的 CNN 模型 ConvNeXt-XL 為例,我們將展示 Tensor Parallel 卷積神經(jīng)網(wǎng)絡(luò)訓(xùn)練的實(shí)現(xiàn)。DTensor 放置方式如下:
模型參數(shù):Replicate
重復(fù)放置在各個(gè) GPU 上,模型包含 3.50 億個(gè)參數(shù),以 FP32 存儲(chǔ)時(shí)占據(jù) 1.4GB GPU 內(nèi)存。
模型輸入:Shard(3)
切分(N, C, H, W)的 W 維度,將輸入分片放到各個(gè) GPU 上。例如,在 4 個(gè) GPU 上對(duì)形狀為(7, 3, 512, 2048) 的輸入執(zhí)行 Shard(3) 會(huì)生成四個(gè)切片,形狀為 (7, 3, 512, 512)。
激活值:Shard(3)
切分(N, C, H, W)的 W 維度,將激活值分片放在各個(gè) GPU 上
模型參數(shù)的梯度:Replicate
重復(fù)放置在各個(gè) GPU 上。
優(yōu)化器狀態(tài):Replicate
重復(fù)放置在各個(gè) GPU 上。
上述配置可以通過(guò) DTensor 提供的 API 來(lái)實(shí)現(xiàn),且用戶(hù)只需指明模型參數(shù)和模型輸入的放置方式,其他張量的放置方式會(huì)自動(dòng)生成。
而要達(dá)成張量并行的訓(xùn)練,我們需要給卷積算子 aten.convolution 和 aten.convolution_backward 注冊(cè)傳播規(guī)則,這將根據(jù)輸入 DTensor 的放置方式來(lái)確定輸出 DTensor 的放置方式:
aten.convolution
Input 放置方式為 Shard(3),weight 和 bias 放置方式為 Replicate,output 放置方式為 Shard(3)
aten.convolution_backward
grad_output 放置方式為 Shard(3),weight和 bias 放置方式為 Replicate,grad_input 放置方式為 Shard(3),grad_weight 和 grad_bias 方式方式為 _Partial
放置方式為 _Partial 的 DTensor,在使用其數(shù)值時(shí)會(huì)自動(dòng)執(zhí)行規(guī)約操作,默認(rèn)規(guī)約算子為求和。
接下來(lái),我們便要給出張量并行的卷積算子前向和反向的實(shí)現(xiàn)。由于將激活值切分到了多個(gè) GPU 上,1 個(gè) GPU 上的本地卷積可能需要相鄰 GPU 上激活值的邊緣數(shù)據(jù),這就需要 GPU 之間進(jìn)行通信。在 ConvNeXt-XL 模型中,其降采樣層的卷積不存在該問(wèn)題,而 Block 中的逐深度卷積則需要處理該問(wèn)題。
如果無(wú)需交換數(shù)據(jù),用戶(hù)可以直接調(diào)用卷積的前向和反向算子,傳入本地張量即可。如果需要交換本地激活值張量邊緣數(shù)據(jù),則使用如圖 1 和圖 2 所示的卷積前向算法和反向算法,省略了圖中的 N 和 C 維度,并假設(shè)卷積核大小為 5x5,padding 為 2,stride 為 1。

圖 1 張量并行卷積前向算法示意圖
如圖 1 所示,當(dāng)卷積核大小為 5x5,padding 為 2,stride 為 1 時(shí),每個(gè) GPU 上的本地 input 都需要取用相鄰 GPU 的寬度為 2 的輸入邊緣,并將收到的邊緣數(shù)據(jù)拼接到自身上。換句話(huà)說(shuō),需要 GPU 間的通信來(lái)確保張量并行卷積的正確性。這種數(shù)據(jù)交換,可以通過(guò)調(diào)用 PyTorch 封裝的 NCCL 發(fā)送接受通信算子來(lái)實(shí)現(xiàn)。
值得一提的是,在多個(gè) GPU 上存在激活切片時(shí),卷積算子的有些 padding 是不需要的。因此本地卷積前向傳播完成后,需要切除 output 中由不需要的 padding 引入的無(wú)效像素,如圖 1 中的藍(lán)色條所示。
圖 2 顯示了張量并行卷積的反向傳播。首先,在梯度輸出上應(yīng)用 zero padding,這與前向傳播過(guò)程中的輸出切除操作相對(duì)應(yīng)。對(duì)本地輸入同樣要進(jìn)行數(shù)據(jù)交換、拼接和 padding 操作。
之后,通過(guò)調(diào)用每個(gè) GPU 上的卷積反向算子,即可獲得權(quán)重梯度、偏置梯度和梯度輸入。
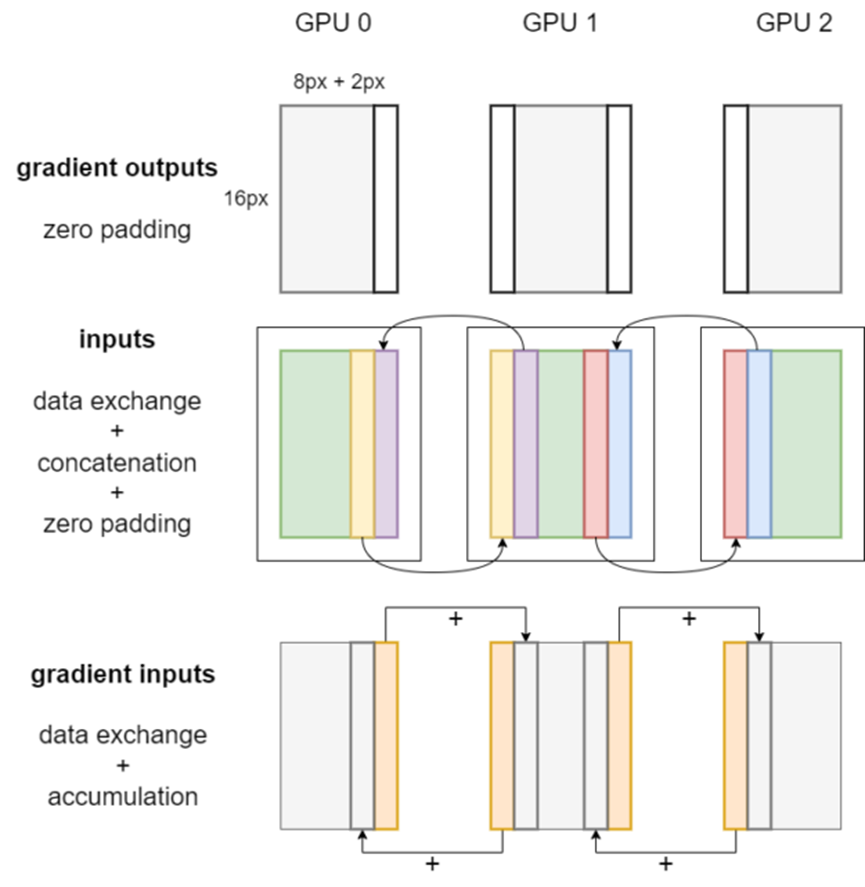
圖 2 張量并行卷積反向傳播工作流程
權(quán)重梯度和偏置梯度的 DTensor 放置方式是 _Partial,因此使用時(shí)會(huì)自動(dòng)對(duì)它們的值進(jìn)行多 GPU 規(guī)約操作。梯度輸入的 DTensor 放置方式是 Shard(3)。
最后,本地梯度輸入的邊緣像素會(huì)被發(fā)送到鄰近 GPU 并在相應(yīng)位置累積,如圖 2 中的橙色條所示。
除了卷積層之外,ConvNeXt-XL 還有一些層需要處理以支持張量并行訓(xùn)練。例如我們需要為 DropPath 層使用的 aten.bernoulli 算子傳播規(guī)則。該算子應(yīng)被置于隨機(jī)數(shù)生成追蹤器的分布式區(qū)域內(nèi),以保證各個(gè) GPU 上的一致性。
所有代碼已經(jīng)并入了 PyTorch GitHub repo 的主分支,用戶(hù)使用時(shí)直接調(diào)用 DTensor 的上層 API 便可實(shí)現(xiàn)張量并行的卷積神經(jīng)網(wǎng)絡(luò)訓(xùn)練。
使用張量并行訓(xùn)練 ConvNeXt 的基準(zhǔn)效果
我們?cè)?nbsp;NVIDIA DGX AI 平臺(tái)上進(jìn)行了基準(zhǔn)測(cè)試,研究 ConvNeXt-XL 訓(xùn)練的速度和 GPU 內(nèi)存占用。梯度檢查點(diǎn)技術(shù)和 DTensor 是兼容的,并且結(jié)合兩項(xiàng)技術(shù),GPU 的內(nèi)存占用能夠更顯著地降低。
測(cè)試的基線(xiàn)是在 1 個(gè) NVIDIA GPU 上使用 PyTorch 原生 Tensor,輸入大小為(7, 3, 512, 1024)時(shí)的結(jié)果:不使用梯度檢查點(diǎn)時(shí) GPU 內(nèi)存占用為 43.28 GiB,一次訓(xùn)練迭代時(shí)間為 723 ms;使用梯度檢查點(diǎn)時(shí) GPU 內(nèi)存占用為 11.89 GiB,一次訓(xùn)練迭代時(shí)間為 934 ms。
全部測(cè)試結(jié)果如圖 3 和圖 4 所示:全局輸入形狀為 (7,3,512,W),其中 W 從 1024 到 8192 不等。實(shí)線(xiàn)為未使用梯度檢查點(diǎn)時(shí)的結(jié)果,虛線(xiàn)為使用梯度檢查點(diǎn)時(shí)的結(jié)果。

圖 3 各種測(cè)試條件下的 GPU 內(nèi)存占用
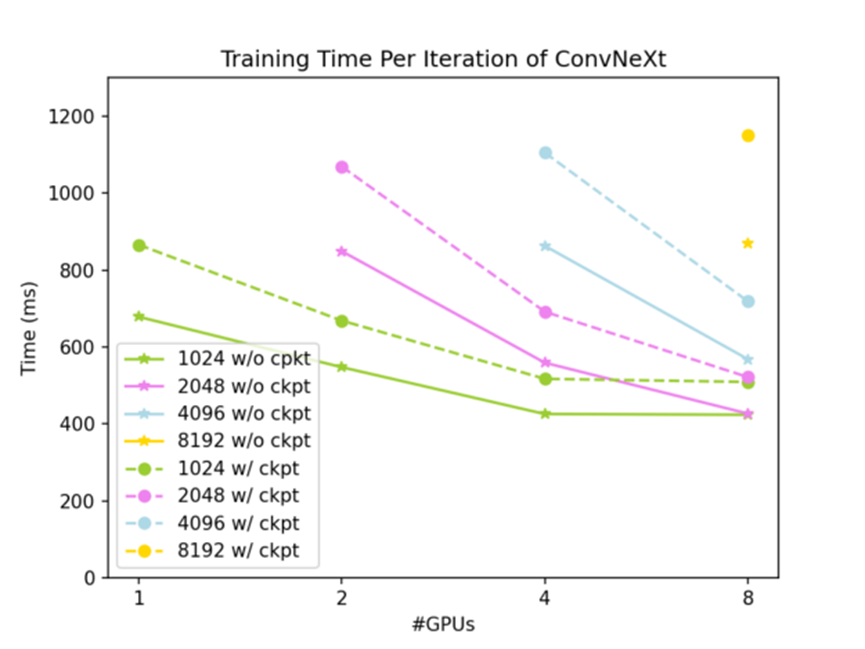
圖 4 各種測(cè)試條件下一次訓(xùn)練迭代耗時(shí)
如圖 3 所示,使用 DTensor 切分激活值可以有效降低 ConvNeXt-XL 訓(xùn)練的 GPU 內(nèi)存占用,并且同時(shí)使用 DTensor 和梯度檢查點(diǎn),ConvNeXt-XL 訓(xùn)練的 GPU 內(nèi)存占用可以降到很低的水平。如圖 4 所示,張量并行方法有很好的弱擴(kuò)展性;在問(wèn)題規(guī)模足夠大時(shí),也有不錯(cuò)的強(qiáng)擴(kuò)展性。下面是不使用梯度檢查點(diǎn)時(shí)的擴(kuò)展性:
全局輸入(7, 3, 512, 2048)給 2 個(gè) GPU 時(shí),一次迭代時(shí)間為 937 ms
全局輸入(7, 3, 512, 4096)給 4 個(gè) GPU 時(shí),一次迭代時(shí)間為 952 ms
全局輸入(7, 3, 512, 4096)給 8 個(gè) GPU 時(shí),一次迭代時(shí)間為 647 ms
結(jié)論
蔚來(lái)自動(dòng)駕駛開(kāi)發(fā)平臺(tái)(NADP)是蔚來(lái)專(zhuān)門(mén)用于研發(fā)核心自動(dòng)駕駛服務(wù)的平臺(tái)。該平臺(tái)可提供高性能計(jì)算和全鏈工具,用來(lái)處理每天成千上萬(wàn)的日常推理和訓(xùn)練任務(wù),以確保主動(dòng)安全和駕駛輔助功能的持續(xù)演進(jìn)。使用 DTensor 實(shí)現(xiàn)的張量并行 CNN 訓(xùn)練能夠有效提高 NADP 上的訓(xùn)練效率。
該關(guān)鍵性的方案使得 NADP 能夠進(jìn)行萬(wàn)卡規(guī)模的并行計(jì)算,它提高了對(duì) GPU 的利用率,降低了訓(xùn)練模型的成本,支持了更靈活的模型結(jié)構(gòu)。基準(zhǔn)測(cè)試顯示,在蔚來(lái)自動(dòng)駕駛場(chǎng)景下,該方法表現(xiàn)良好,有效解決了視覺(jué)大模型的訓(xùn)練難題。
基于 PyTorch DTensor 的張量并行 CNN 訓(xùn)練可顯著減少內(nèi)存占用并保持良好的可擴(kuò)展性。我們預(yù)計(jì)該方法將充分利用多個(gè) GPU 的算力和互連功能,使感知模型訓(xùn)練更加普及。
上一篇:深入解讀毫米波雷達(dá)原理與應(yīng)用
下一篇:電動(dòng)汽車(chē)應(yīng)用—OBC, DC/DC, PDU多合一產(chǎn)品方案
 汽車(chē)電工電子技術(shù)基礎(chǔ)實(shí)驗(yàn)實(shí)訓(xùn)指導(dǎo)書(shū)
汽車(chē)電工電子技術(shù)基礎(chǔ)實(shí)驗(yàn)實(shí)訓(xùn)指導(dǎo)書(shū) TLC082CDGN
TLC082CDGN





- 鈉離子電池的技術(shù)突破可能是電動(dòng)汽車(chē)未來(lái)發(fā)展的關(guān)鍵
- 創(chuàng)新型新型粘合劑使性能翻倍 有望大大提升電動(dòng)汽車(chē)電池的耐用性
- 大功率線(xiàn)圈的研發(fā)進(jìn)展證明電動(dòng)汽車(chē)無(wú)線(xiàn)充電技術(shù)已準(zhǔn)備就緒
- 更強(qiáng)、更快、更輕:研究人員為電動(dòng)汽車(chē)研發(fā)更高性能的新型鋼材
- 革命性的單晶合成技術(shù)提高了電動(dòng)汽車(chē)電池的使用壽命
- 汽車(chē)產(chǎn)業(yè)搞 AI,要 “支棱” 起來(lái)
- 車(chē)聯(lián)網(wǎng)功能普及加速 5G 網(wǎng)絡(luò)、FOTA 升級(jí)等將進(jìn)入快速上車(chē)階段
- 為什么快速充電會(huì)降低汽車(chē)電池的容量?
- 集成變壓器模塊技術(shù)混動(dòng)和純電動(dòng)汽車(chē)?yán)m(xù)航里程的新助力

- HV823,用于個(gè)人數(shù)字助理的 1 燈通用燈驅(qū)動(dòng)器
- LTC3873IDDB-5、5V 輸出非隔離式電信家政電源的典型應(yīng)用電路
- LTC3429、2 節(jié)電池至 3.3V 同步升壓轉(zhuǎn)換器
- ADM00310,用于 16 位 MCU 系統(tǒng)的 ADC 評(píng)估板提供評(píng)估 MCP3903 六通道 Sigma-Delta ADC 性能的能力
- NE555使led燈閃爍
- OM13526UL:PCAL6524 Fm+ I2C 24位通用IO演示板
- ADR550A 5V 輸出高精度并聯(lián)模式電壓基準(zhǔn)的典型應(yīng)用
- type-c 轉(zhuǎn)串口 miniTTL 可調(diào)電壓, 線(xiàn)序
- LD2330語(yǔ)音識(shí)別模塊_智能垃圾桶底板_V1.0_20200115_[驗(yàn)證成功]
- KITFS84SKTEVM: FS84 QFN48EP Safety SBC編程板






- TLC2543和TLV5614的STM32程序
- 兆歐表容量指標(biāo)的定義方法有哪些
- 基美電子推出用于汽車(chē)的下一代超級(jí)電容器
- CEVA 和 Mimi 合作為 真正無(wú)線(xiàn)耳機(jī)市場(chǎng)推動(dòng)輔助聽(tīng)力發(fā)展
- STM32單片機(jī)-增量式PID
- 德州儀器出席 2023 年教育部產(chǎn)學(xué)合作協(xié)同育人項(xiàng)目對(duì)接會(huì), 并榮獲優(yōu)秀項(xiàng)目案例獎(jiǎng)
- Rambus通過(guò)業(yè)界領(lǐng)先的24Gb/s GDDR6 PHY提升AI性能
- 從實(shí)驗(yàn)室到工業(yè)場(chǎng)景:優(yōu)艾智合密集發(fā)布7款人形機(jī)器人
- 地表最酷人形機(jī)器人,拿下新一輪2億元融資
- 自動(dòng)駕駛警示:沒(méi)有企業(yè)能完全避免自動(dòng)駕駛在復(fù)雜環(huán)境中的失誤
- 高階就高級(jí)嗎?我們到底該如何使用智能駕駛輔助?
- 即將迎來(lái)第三代?嵐圖固態(tài)電池研發(fā)進(jìn)展曝光
- 一文了解2025年3月的固態(tài)電池大事件!
- 傳統(tǒng)鋰電、半固態(tài)、固態(tài)電池終極對(duì)決:誰(shuí)將主宰新能源未來(lái)?
- 國(guó)產(chǎn)智駕迎戰(zhàn)特斯拉FSD,背后AI含量差幾何?
- 左手AI,右手機(jī)器人,半導(dǎo)體巨頭英飛凌的新故事
- 激光雷達(dá)的復(fù)仇
- ADI電磁流量計(jì)解決方案
- [有獎(jiǎng)轉(zhuǎn)發(fā)]Vishay新能源、航天/軍工解決方案
- 如何突破時(shí)域和頻域測(cè)試的壁壘?
- “搜器件”小程序又添新功能!
- 【貝能好禮相送】我們拼啦 尋覓Infineon 調(diào)光恒流LED驅(qū)動(dòng)器 ICL5102寫(xiě)真
- Maxim 利用nanoPower創(chuàng)新技術(shù),致力于降低系統(tǒng)的靜態(tài)功耗 看視頻答題贏好禮! 還有免費(fèi)開(kāi)發(fā)板等你拿
- 恩智浦開(kāi)發(fā)板交流火熱進(jìn)行中
- ADI有獎(jiǎng)下載活動(dòng)之15 ADI公司智能可穿戴醫(yī)療保健設(shè)備解決方案
- 直播已結(jié)束【英飛凌全新Wi-Fi6單芯片SoC助力物聯(lián)網(wǎng)產(chǎn)品的快速開(kāi)發(fā)】(9:30入場(chǎng))
- 2021年中國(guó)存儲(chǔ)芯片行業(yè)發(fā)展現(xiàn)狀
- PHILIPS 51LPC系列單片機(jī)的應(yīng)用
- 賣(mài)掉波士頓動(dòng)力后,軟銀又28億美元收購(gòu)機(jī)器人公司
- 如何利用單片機(jī)從LCD顯示屏上讀出所測(cè)得電阻值
- 3年砸1000億美元擴(kuò)產(chǎn),臺(tái)積電在美建廠(chǎng)只是剛剛開(kāi)始
- Vishay汽車(chē)級(jí)DC-Link 薄膜電容器可在高濕環(huán)境下穩(wěn)定工作
- 特斯拉股價(jià)暴跌21%:未被納入標(biāo)普500 專(zhuān)家揭秘!
- 技術(shù)科普—5G小基站有何玄機(jī)
- 三星晶圓代工在贏一單,拿下高通5G AP訂單
- 72核心+7nm工藝,新一代ARM處理器將賦予超算新魔力
- 做單片機(jī)產(chǎn)品的時(shí)候,實(shí)驗(yàn)室里都有什么儀器,工具及他們的品牌?
- ucosII內(nèi)核詳解zz
- 【CN0087】利用 AD5734 DAC 提供 14 位、 四通道、單極性/雙極性電壓輸出
- 電源模塊紋波和噪聲的區(qū)別
- stm32 ADC 中斷速度出現(xiàn)的速率 只有12k/秒
- Win CE下文件拷貝容易被損壞的原因?
- 實(shí)驗(yàn)LIS25BA骨振動(dòng)傳感器采集音頻
- 【micropython】STM32中對(duì)I2C初始化進(jìn)行優(yōu)化
- 好書(shū)推薦
- 關(guān)于一個(gè)單片機(jī)串口接收FPGA配置文件的問(wèn)題,希望大家不吝賜教







 京公網(wǎng)安備 11010802033920號(hào)
京公網(wǎng)安備 11010802033920號(hào)