機器使用相機觀察現實世界并解釋其中數據的能力將對其應用產生更大的影響。無論是像 Starship 機器人這樣的簡單送餐機器人,還是像特斯拉這樣的先進自動駕駛汽車,它們都依賴從高度復雜的攝像頭獲取的信息來做出決定。在本教程中,我們將學習如何通過閱讀圖像上的字符來識別圖像中的細節。這稱為光學字符識別(OCR)。
這為許多應用程序打開了大門,例如自動讀取名片中的信息、從名稱板上識別商店或識別道路上的標志板等等。我們中的一些人可能已經通過 Google Lens 體驗過這些功能,所以今天我們將使用來自Google Tesseract-OCR 引擎的光學字符識別 (OCR)工具以及 python 和 OpenCV 構建類似的東西,以使用Raspberry Pi識別圖片中的字符。
Raspberry pi 是一種便攜式且功耗更低的設備,用于許多實時圖像處理應用,如人臉檢測、 對象跟蹤、 家庭安全系統、監控攝像頭等。
先決條件
如前所述,我們將使用 OpenCV 庫來檢測和識別人臉。因此,在繼續本教程之前,請確保在 Raspberry Pi 上安裝 OpenCV 庫。還可以使用 2A 適配器為您的 Pi 供電,并將其連接到顯示監視器以便于調試。
本教程不會解釋OpenCV的工作原理,如果您有興趣學習圖像處理,請查看此OpenCV 基礎知識和高級圖像處理教程。您還可以在此使用 OpenCV 的圖像分割教程中了解輪廓、斑點檢測等。
在樹莓派上安裝 Tesseract
要在 Raspberry Pi 上執行光學字符識別,我們必須在 Pi 上安裝 Tesseract OCR 引擎。為此,我們必須首先配置 Debian 軟件包 (dpkg),這將幫助我們安裝 Tesseract OCR。在終端窗口中使用以下命令來配置 Debian Package。
sudo dpkg - -configure -a
然后我們可以繼續使用 apt-get 選項安裝 Tesseract OCR (光學字符識別)。下面給出了相同的命令。
sudo apt-get install tesseract-ocr
您的終端窗口將如下所示,安裝完成大約需要 5-10 分鐘。
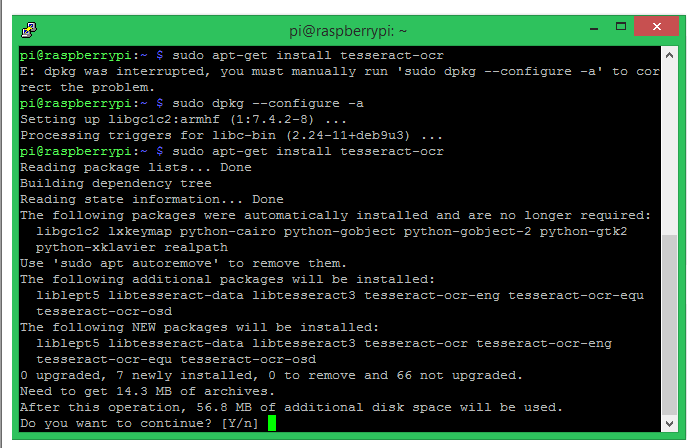
現在我們已經安裝了 Tesseract OCR,我們必須使用 pip install package 安裝 PyTesseract 包。Pytesseract 是圍繞 tesseract OCR 引擎的 python 包裝器,它幫助我們將 tesseract 與 python 一起使用。按照以下命令在 python 上安裝 pytesseract。
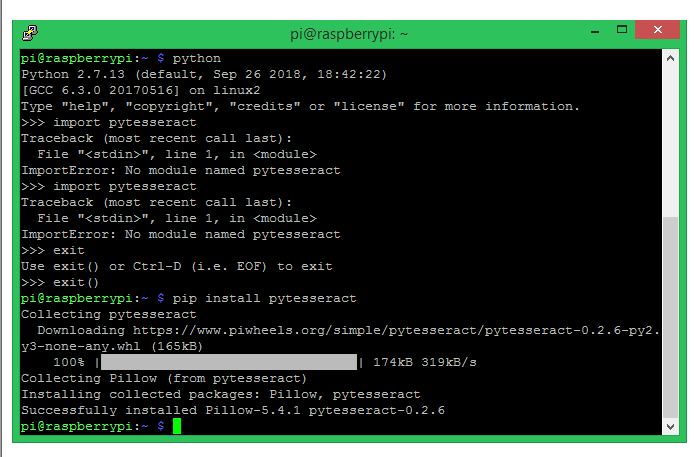
點安裝 pytesseract
在進行此步驟之前,請確保已經安裝了枕頭。學過樹莓派人臉識別教程的人應該已經安裝好了。其他人可以使用該教程并立即安裝。pytesseract 安裝完成后,您的窗口將如下所示
Windows/Ubuntu 上的 Tesseract 4.0
Tesseract 光學字符識別項目最初由 Hewlett Packard 于 1980 年啟動,然后被 Google 采用,該項目一直保持至今。多年來,Tesseract 不斷發展,但它仍然只在受控環境中運行良好。如果圖像有太多的背景噪音或失焦,則 tesseract 似乎無法正常工作。
為了克服這個問題,最新版本的 tesseract Tesseract 4.0 使用深度學習模型來識別字符甚至筆跡。Tesseract 4.0 使用長短期記憶 (LSTM) 和循環神經網絡 (RNN) 來提高其 OCR 引擎的準確性。不幸的是,在本教程的這個時候,Tesseract 4.0 僅適用于 Windows 和 Ubuntu,但仍處于 Raspberry Pi 的 beta 階段。所以我們決定在 Windows 上試用 Tesseract 4.0,在 Raspberry Pi 上試用 Tesseract 3.04。
Pi上的簡單字符識別程序
因為我們已經在 PI 中安裝了Tesseract OCR和 Pytesseract 包。我們可以快速編寫一個小程序來檢查字符識別是如何處理測試圖像的。我使用的測試圖像、程序和結果可以在下圖中找到。

如您所見,該程序非常簡單,我們甚至沒有使用任何 OpenCV 包。上面的程序在下面給出
from PIL import Image
img =Image.open (‘1.png’)
text = pytesseract.image_to_string(img, config=‘’)
print (text)
在上面的程序中,我們試圖從位于程序同一目錄內的名為“1.png”的圖像中讀取文本。Pillow 包用于打開此圖像并將其保存在變量名img下。然后我們使用pytesseract 包中的image_to_sting方法檢測圖像中的任何文本,并將其保存為變量 text 中的字符串。最后我們打印文本的值來檢查結果。
如您所見,原始圖像實際上包含文本“解釋那些東西!01234567890 ”這是一個完美的測試圖像,因為我們在圖像中有字母、符號和數字。但是我們從 pi 得到的輸出是“解釋那些東西!Sdfosiefoewufv”這意味著 out 程序無法識別圖像中的任何數字。為了克服這個問題,人們通常使用 OpenCV 從程序中去除噪聲,然后根據圖像配置 Tesseract OCR 引擎以獲得更好的結果。但請記住,您不能期望 Tesseract OCR Python 提供 100% 可靠的輸出。
配置 Tesseract OCR 以改進結果
Pytesseract 允許我們通過設置更改圖像搜索字符方式的標志來配置 Tesseract OCR 引擎。配置 Tesseract OCR 時使用的三個主要標志是語言 (-l)、OCR 引擎模式 (--oem) 和頁面分段模式 (- -psm )。
除了默認的英語,Tesseract 還支持許多其他語言,包括印地語、土耳其語、法語等。我們在這里只使用英語,但您可以從官方github 頁面下載訓練數據并將其添加到您的包中以識別其他語言。 還可以從同一圖像中識別兩種或多種不同的語言。語言由標志 -l設置,要將其設置為一種語言,請使用代碼和標志,例如對于英語,它將是-l eng,其中 eng 是英語的代碼。
下一個標志是 OCR Engine Mode,它有四種不同的模式。每種模式都使用不同的算法來識別圖像中的字符。默認情況下,它使用隨包安裝的算法。但我們可以將其更改為使用 LSTM 或神經網絡。四種不同的引擎模式如下所示。該標志由--oem 指示,因此要將其設置為模式 1,只需使用--oem 1。

最后也是最重要的標志是頁面分割模式標志。當您的圖像具有如此多的背景細節以及字符或字符以不同的方向或大小書寫時,這些非常有用。共有 14 種不同的頁面分割模式,所有這些都在下面列出。該標志由–psm指示,因此設置模式為 11。它將是–psm 11。
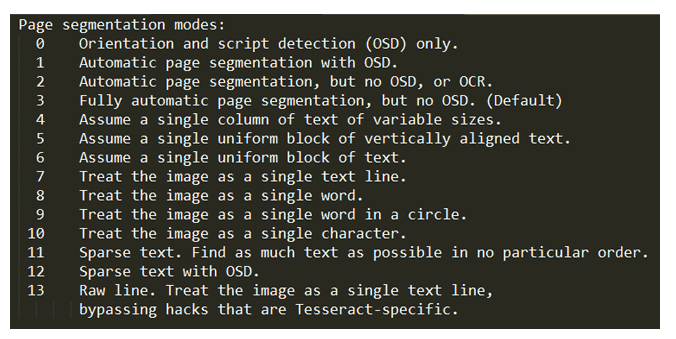
在 Tesseract Raspberry Pi 中使用 oem 和 psm 以獲得更好的結果
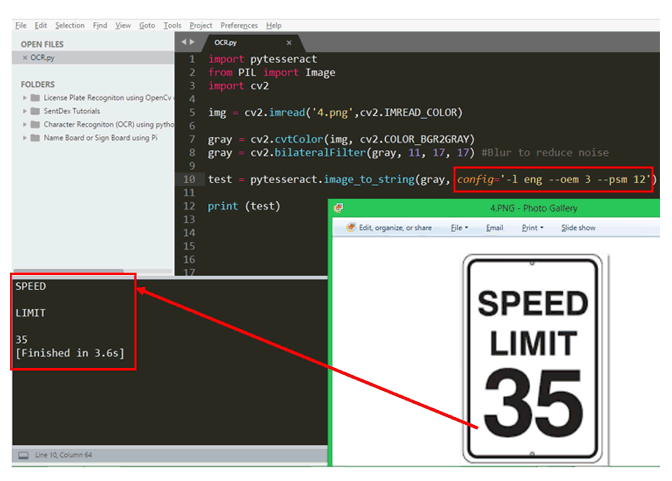
讓我們檢查一下這些配置模式的有效性。在下圖中,我嘗試識別限速板上的字符,上面寫著“ SPEED LIMIT 35 ”。如您所見,與其他字母相比,數字 35 的尺寸更大,這使 Tesseract 感到困惑,因此我們僅得到“SPEED LIMIT”的輸出,并且缺少數字。
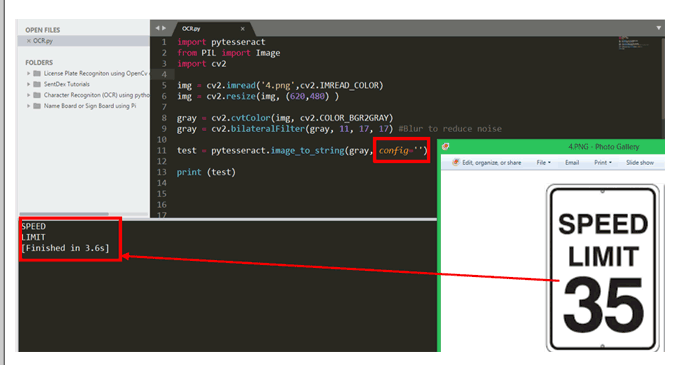
為了克服這個問題,我們可以設置配置標志。在上面的程序中,配置標志是空的 config=‘’,現在讓我們使用上面提供的詳細信息來設置它。圖像中的所有文本都是英文,所以語言標志是 -l eng,OCR 引擎可以保留為默認模式 3 所以 -oem 3。現在終于在 psm 模式下,我們需要從圖像中找到更多的字符,所以我們在這里使用模式 11,它變成了 –psm 11。最后的配置行看起來像
測試= pytesseract.image_to_string(灰色,配置=‘-l eng --oem 3 --psm 12’)
相同的結果可以在下面找到。正如您現在所看到的,Tesseract 能夠從圖像中找到所有字符,包括數字。
通過置信水平提高準確性
Tesseract 中另一個有趣的特性是image_to_data方法。該方法可以為我們提供詳細信息,例如圖像中字符的位置、檢測的置信度、行和頁碼。讓我們嘗試在示例圖像上使用它
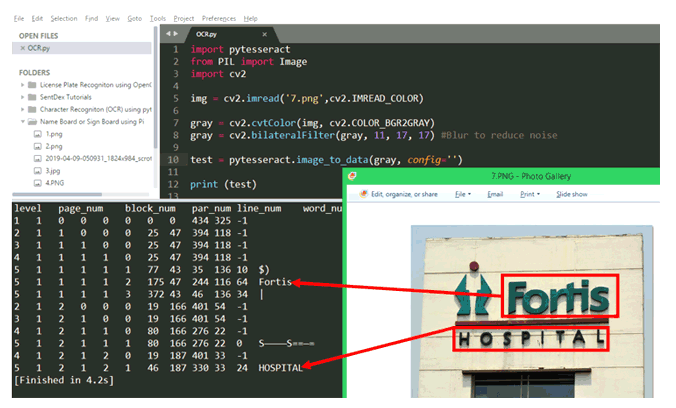
在這個特定的例子中,我們得到了很多噪聲信息以及原始信息。圖片是一家名為“富通醫院”的醫院的名字牌。但是除了名稱之外,圖像還具有其他背景細節,例如徽標構建等。因此,Tesseract 嘗試將所有內容都轉換為文本,并給我們帶來了很多噪音,例如“$C”“|” “S_______S==+”等。
現在在這些情況下image_to_data方法就派上用場了。如您所見,上述光學字符識別算法返回其已識別的每個字符的置信度,Fortis 的置信度為 64,HOSPITAL 的置信度為 24。對于其他噪聲信息,置信度值為 10 或以下大于 10。這樣我們就可以過濾掉有用的信息,利用置信度的值來提高準確率。
樹莓派上的 OCR
雖然使用 Tesseract 時在 Pi 上的結果不是很令人滿意,但它可以與 OpenCV 結合以濾除圖像中的噪聲,如果圖像良好,可以使用其他配置技術獲得不錯的結果。我們已經在 Pi 上使用 tesseract 嘗試了大約 7 種不同的圖像,并且通過相應地調整每張圖片的模式來獲得接近的結果。完整的項目文件可以下載為該位置的 Zip,其中包含所有測試圖像和基本代碼。
讓我們在 Raspberry Pi 上再嘗試一個示例板標志,這一次非常簡單明了。下面給出了相同的代碼
從 PIL 導入 pytesseract 導入圖像
導入cv2
img = cv2.imread(‘4.png’,cv2.IMREAD_COLOR) #打開要識別字符的圖像
#img = cv2.resize(img, (620,480) ) #如果需要,調整圖像大小
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) #轉換為灰色以減少
細節 gray = cv2.bilateralFilter(gray, 11, 17, 17) #模糊以減少噪點
original = pytesseract.image_to_string(gray, config=‘’)
#test = (pytesseract.image_to_data(gray, lang=None, config=‘’, nice=0) ) #get confidence level if required
#print(pytesseract.image_to_boxes(灰色的))
打印(原件)
該程序打開我們需要從中識別字符的文件,然后將其轉換為灰度。這將減少圖像中的細節,使 Tesseract 更容易識別字符。為了進一步減少背景噪聲,我們使用 OpenCV 中的一種雙邊濾波器對圖像進行模糊處理。最后,我們開始從圖像中識別字符并將其打印在屏幕上。最終的結果將是這樣的。

希望您理解本教程并喜歡學習新知識。OCR 用于許多地方,如自動駕駛汽車、車牌識別、路牌識別導航等,在 Raspberry Pi 上使用它為更多可能性打開了大門,因為它可以便攜且緊湊。
導入 pytesseract
從 PIL 導入圖像
導入簡歷2
img = cv2.imread(’4.png’,cv2.IMREAD_COLOR) #打開要識別字符的圖像
#img = cv2.resize(img, (620,480) ) #如果需要調整圖像大小
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) #轉換為灰色以減少細節
gray = cv2.bilateralFilter(gray, 11, 17, 17) #Blur 去噪
原始= pytesseract.image_to_string(灰色,配置=’’)
#test = (pytesseract.image_to_data(gray, lang=None, config=’’, nice=0) ) #get confidence level if required
#print(pytesseract.image_to_boxes(灰色))
打印(原件)
’’’必需 = ’abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ’
最終 = ’’
對于原始的 c:
對于需要的ch:
如果 c==ch:
最終 = 最終 + c
休息
打印(測試)
在測試中:
如果 a == "
":
打印(“找到”)’’’
這里還沒有內容,您有什么問題嗎?
電子電路資源推薦
- 開關穩壓電源——原理、設計與實用電路

來源:下載中心
- 電機啟蒙系列教程

來源:大學堂
- 開源閉環步進電機控制器(原理圖+源代碼)
來源:下載中心
- 直流電橋原理及操作
來源:大學堂
- 單片機運行原理的一點點總結

來源:電路圖
- 電阻和電阻定律以及0歐電阻和上、下拉電阻的作用
來源:電路圖


推薦帖子 最新更新時間:2025-04-12 15:34
- 負電源軌不會消失(轉)
- 背景 負電源軌與主要的 IC 構件配合使用,例如:數模轉換器 (DAC)、模數轉換器(ADC)、運算放大器和 GaAs FET 偏置電路等。對稱的電源 (軌) 可處理 AC 信號,并且不會產生 DC 偏移。顯然,假如僅存在一個正電源軌,那么輸出信號通常只能采取正值 (取決
qwqwqw2088
 模擬與混合信號
模擬與混合信號
- 基于MSP430超低功耗設計的超聲波測距學習資料
- 超聲波測距,低功耗設計 基于MSP430超低功耗設計的超聲波測距學習資料 下載,頂 學習一下 感謝分享 感謝分享 感謝分享 謝謝奉獻! 謝謝分享,學習下 好貼,支持樓主分享,頂 謝謝樓主 支持!呵呵 感謝有你的分享! 感謝樓主
kingheimer
微控制器 MCU
- Ti launchPad在XP下的驅動
- Ti launchPad在XP下有三個驅動要安裝,有兩個已經成功安裝,最后一個端口(串口)下的驅動怎么也裝不上,一直顯示一個黃色的“!”,尋求幫助 Ti launchPad在XP下的驅動 tiva c的嗎? 有裝CCS嗎? 用的Keil, tiva C win7 下安裝很順利,
liulanger521
微控制器 MCU
- 用賽靈思,怎樣把要顯示的mif文件導入rom模塊
- 網上一個關于VGA顯示的教程說:“說將要顯示的圖片轉成mif文件,然后導入rom模塊” 如果用xilinx,用ip核生成rom時添加的是coe文件,那么這個要顯示的mif文件怎樣導入呢? \0\0\0eeworldpostqq 用賽靈思,怎樣把要顯示的mif文件導入rom模塊
藍貓淘氣
FPGA/CPLD
- fedora15&TQ210開發板QT環境搭建(轉)
- PC: linux-fedora15 platform:TQ210-S5PV210+7寸電容屏 源碼準備: 觸摸屏校正程序: http://sourceforge.net/projects/tslib.berlios/files/ qt libraries: http://
小小宇宙
ARM技術
- 基于無線傳感網絡的工地環境檢測(PM2.5)
- 本人做畢設,題目是基于 無線傳感網絡 的工地環境檢測,用的傳感器是夏普GP2Y1010AU0F這個傳感器,現在大致底層板的電路已經出來,只是在這個傳感器和 CC2530 怎么連接問題,在網上找了許久,沒有比較詳細的參考資料和相關電路分析,我用的 電路是這樣的,
ecjtuy
無線連接
- 金剛狼套件即將發布
- 新手學Tiva LunchPad求指導
- STM8程序燒錄
- 【Atmel SAM R21創意大賽周計劃】+(ZLLDEMO+SLRemote)驅動LED0演示
- STM32中文參考資料
- DIY手機+藍雨夜 FM功能測試
- 樹莓派支持的HDMI屏
- 請言簡意賅的說一下Gerber文件
- MSP430F5438A如何下載程序
- MSP430如何進入低功耗模式LPMx.5
- 好書!《代碼大全》
- 主攻“儀器儀表類”賽題的同學注意了--南華大學黃智偉系列
- 能夠檢測到癌細胞的傳感器
- 弱弱的請教各位大神,電動汽車電源系統為何選用72V、96V?
- 單片機系統的幾種硬件加密技術
- 對比方案賽+LM3488和LPD2910升壓39V的對比設計
- DM8168的任務調度周期問題,最簡單的任務也會間歇性出現335ms左右的調度周期
- AM335X_StarterWare_02_00_01_01里怎么沒有TI_SDCard_boot_utility_v1_0.exe?
- 用EnergyTrace+來測試MSP432的低功耗例程,怎么看不到低功耗狀態?
- 【我與WEBENCH】基于LM2596芯片設計的12V -24V轉5V/3A電源設計(實物對比測試)
- TYPE-C測試板
- 用于微處理器系統的 LTC1148-3.3、5V 至 3.3V 轉換器
- L78L15C正壓穩壓器可調輸出穩壓器的典型應用
- 加熱臺量產計劃
- 使用 Nuvoton Technology Corporation 的 W83321G 的參考設計
- DC1783A-D,用于 LTC2376CMS-16、16 位、250 ksps、12.5MHz 低功率、低噪聲模數轉換器的演示板
- 45W 19V 適配器參考板,采用 SOT-223 封裝的 700V CoolMOS?P7 超結 MOSFET
- NCP59801MTADJTAGEVB:NCP59801 WDFNW6 2x2 ADJ 評估板
- ADIS16203/PCBZ,基于 ADIS16203 加速度計傾角計/加速度計的 iSensor 評估板
- LIS2DW12適配器板,標準DIL 24插座







 京公網安備
11010802033920號
京公網安備
11010802033920號